Distributed media processing – Accessing files
While playing with personal projects involving heavy media manipulation (videos and audio), one recurring question that keeps bugging me is the most efficient way (accounting for all tradeoffs) to make the media files available to the different micro-services and jobs.
For example: imagine you are working on a video generator from text, you have the main application service that user can upload image frames too, a service that generates the images, another that takes in images and converts them to videos, another that upscales the generated videos, and another that transcodes the videos.
For whatever reasons (e.g libraries incompatibility, different infrastructure, or different business requirements) you can’t have all these functionalities in a single service.
What is the most efficient way to pass across the videos to the different services for them to work on?
Here is a basic sample sequence diagram
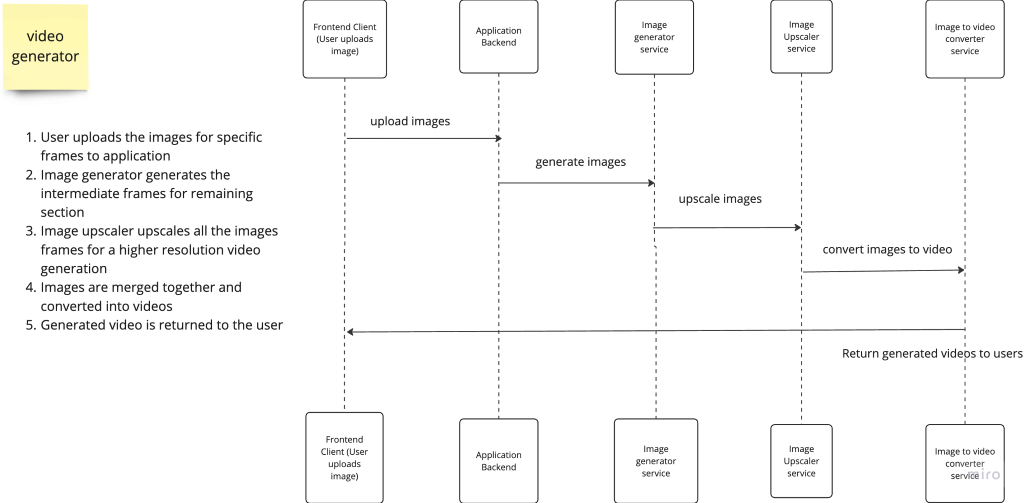
Approach One:
Basically, it’s a lazy brute-force approach.
The most basic approach involves sending the videos as media blobs or video objects across the different service network boundaries. When the different services are done operating on the video, the service responds with a new media object.
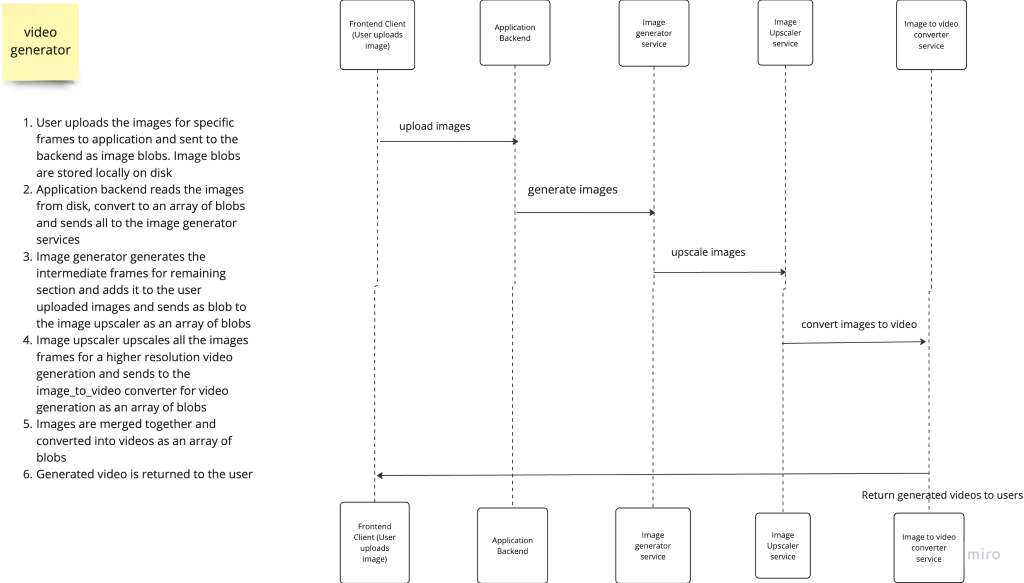
Pros:
- Easy to implement
- It is relatively easy for each service to clean up the user files and temporary files created during the video generation process
- Each service can easily exist independently of the whole system in any infrastructure as long as the endpoints and request interfaces remain the same
Cons:
- Each service maintains a copy of the file which can be memory inefficient. If files are cleaned up immediately then it is more difficult to restart a process without a user re-uploading the file and the services generating new media.
- Memory overhead from having too many requests opened between the services. It is synchronous because each request has to wait for the services to respond with an updated video object. Video processing is historically not the fastest of operations so you end up having a lot of open requests waiting for a response. (You use a queue, pub-sub implementation or some asynchronous operations though so that the services don’t have to wait for a response)
- Unnecessary bandwidth wastage leading to an increased infrastructure cost: Sending gigabytes of videos in the request and response would ramp up your bandwidth cost faster than you can imagine. Working on 10GB of videos for 10 users easily leads to at least 100GB worth of requests and another 100 GB worth of response = 200GB in bandwidth. And 10GB per user can be trivial, 10 users are still a small number of users.
- Wasted RAM and Memory; Before the videos can be sent over the network, you likely have to load the videos in memory. As seen in problem 2, loading 100GB of videos in memory means you have to have a minimum of 100GB RAM/ just for 10 users. (A way to further improve on this would be to stream the media files to the receiving service)
Approach 2:
Upload the media files to an object store e,g S3 and Azure blob storage etc. Each service downloads and when done uploads.
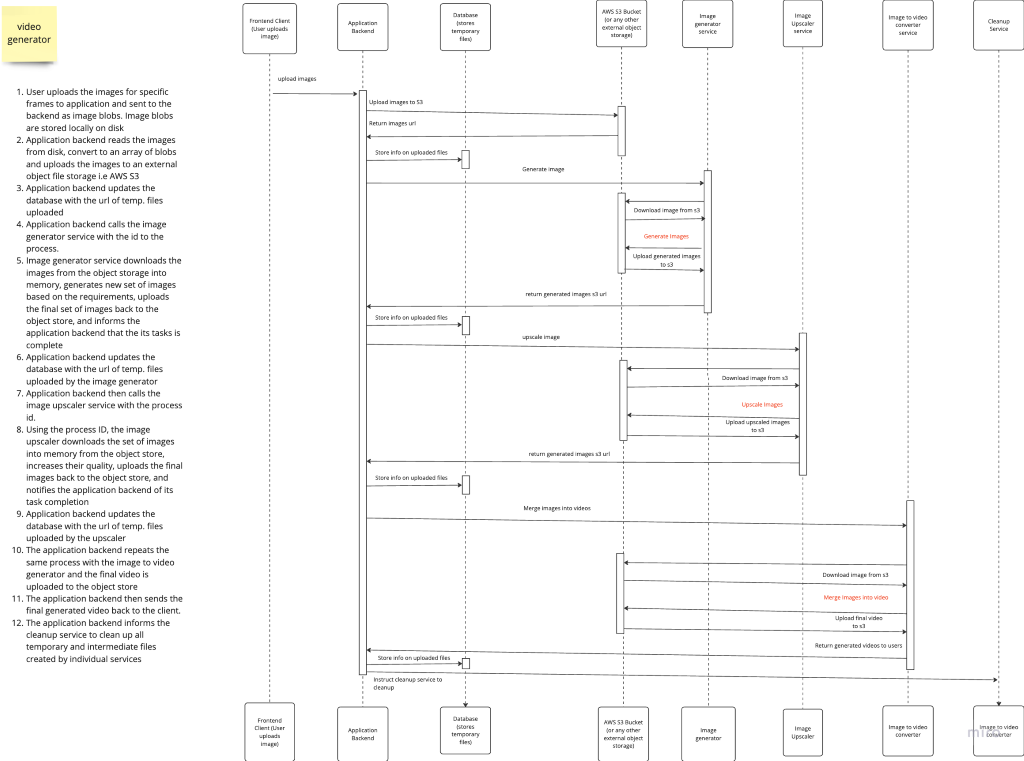
Pros:
- Reduced network overhead. Each service is responsible for their temp files and cleaning them up. If one has a memory leak, no other service is affected
- Process restart on error is easier, especially in an autoscaled environment. If an instance of a service has an error and gets terminated, a new instance can just download the file again and start the video process all over again
Cons:
- An increased complexity when compared with the first approach
- Keeping track of all the intermediary and temp media files uploaded to s3 by the different services in the process of generating the final output videos so they can be cleaned up (deleted) afterwards is an additional complexity
- Still, some memory overhead because each service still has to download the file into memory and upload the files back to the object storage when done
Approach 3:
Shared Files storage mounted on each service e.g. AWS EFS. Since it is a file storage and not an object store, the files don’t need to get downloaded into memory and then re-uploaded. The files just exists automatically to all services that has the external file system mounted. All services have access to the same files and can operate on them.
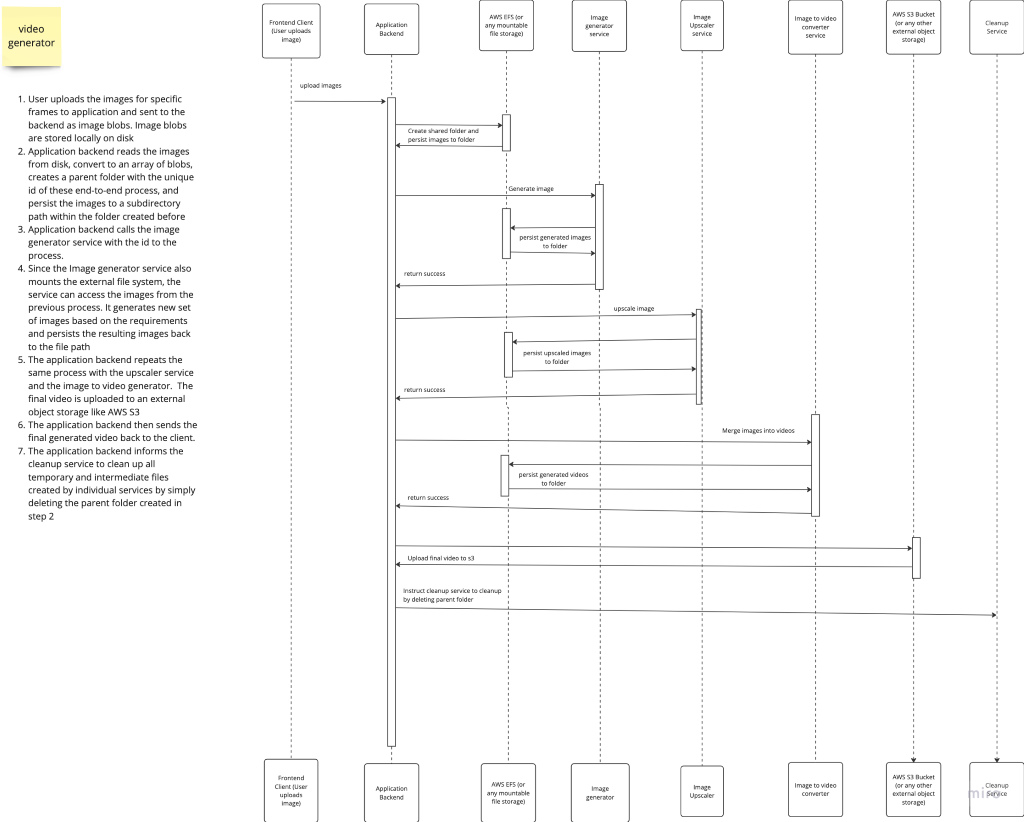
Pros:
- Easy access. Reduced bandwidth usage that would otherwise have been spent downloading and re-uploading media files
- Reduce application complexity since every service is working on the same files/folders instead of creating their own
- If all temporarily created files used for a particular requests share a single parent folder, Then cleanup is relatively easier as the primary application backend can just delete the parent folder of that specific request process on process completed
Cons:
- Coupling of services. The different services cannot just exist in isolation. Since they all have to mount a specific file system
- Increased infrastructure complexity. Each service has to mount an external file system as a regular file path e.g EFS
- A memory leak into the file system of one can affect the other services. e.g. If a service creates a file in a different file path outside the shared parent folder, and forgets to clean it (maybe due to a crash before the process is completed) then that orphan file would forever exist in the shared file system unless another independent process exists to find orphan files and clean them up
Side Note:
Rather than sending requests from one service to another, it is sometimes better to use a queue or some pub/sub mechanism with workers. If your worker processes are atomic enough then an error in one of the services doesn’t terminate the whole end-to-end processes. The service with the error can be restarted and it picks up from where it stopped.